
Wer einen Blog (oder Online-Shop, Social-Media-Kanäle und sonstige Webseiten) betreibt, hat eigentlich immer Bedarf an Bildmaterial.
Nicht immer kommen dafür eigene Fotos in Frage bzw. sind vorhanden.
Bisher greift man in dem Fall üblicherweise auf Stockfotografie zurück. Da gibt es durchaus auch kostenfreie Ansätze wie Pixabay, wo CC0-Lizenzen zur Verwendung kommen.
Perspektivisch könnte noch eine weitere „Quelle“ hinzukommen: KI-generierte Bilder, die z.B. mittels Stable Diffusion (oder einem anderen KI-Bildgenerator) erzeugt werden.
Ich habe ausprobiert, ob KI-Bilder für meine Webseiten und Blogs in Frage kommen. Meine Antwort lautet bisweilen erstmal „Nein“ – genaueres dazu im Folgenden.
Inhaltsverzeichnis
KI-Bildgenerierung per Stable Diffusion, DALL-E, Craiyon, Midjourney usw.
Mein Setup für die Generierung der KI-Bilder auf eigener Hardware – das Stable Diffusion Web UI
Ich nutze mit Stable Diffusion einen von drei derzeit populären Text-zu-Bild-Generatoren, die auf Künstlicher Intelligenz und Deep-Learning basieren.
Neben Stable Diffusion sind derzeit auch DALL-E, Craiyon und Midjourney trending.
Weiterhin will ich eigene Hardware nutzen (sprich den KI-Bildgenerator lokal installieren).
Um schnell und komfortabel zum Ziel zu kommen, habe ich mich für das Stable Diffusion Web UI (von AUTOMATIC1111, siehe Github-Repository) entschieden.
Das ermöglicht einerseits eine schnelle Installation mittels Shell-Script (in meinem Fall: Ubuntu-Linux, aber auch für Windows oder Mac verfügbar).
Anderseits wird eine Browser-Oberfläche mitgeliefert, so dass die Text-Prompts für die Bildgenerierung und andere Parameter schnell verändert werden können und die generierten Bilder direkt angezeigt werden und heruntergeladen werden können.
Wichtig ist noch die Hardware. Empfohlen werden:
- aktuelle Multi-Core CPU
- Nvidia-Grafikkarte mit mindestens 12 GB VRAM (aktuelle AMD-Grafikkarten sowie Apple M1 / M2 ist ebenfalls möglich, jedoch scheinen die Nvidia-Treiber am ausgereiftesten zu sein)
- mindestens 16 GB Arbeitsspeicher
Es geht auch ohne diese Mindestanforderung. Dann geht die Bildgenerierung jedoch teils ewig.
Es ist z.B. auch möglich, AI/ML-Tools wie Stable Diffusion nur über CPU laufen zu lassen. Das ist auch mit dem Stable Diffusion Web UI möglich, jedoch müssen dann folgende Zusatzparameter in die webui-user.sh (siehe hier):
export COMMANDLINE_ARGS="--precision full --no-half --use-cpu all --skip-torch-cuda-test"
export CUDA_VISIBLE_DEVICES=-1Ich habe es interessehalber „CPU-only“ auf vier dedizierten AMD Epyc-Kernen probiert (in einer VM) – und kam bei 30 Schritten mit dem Euler a-Sampler und für ein 512 x 512-Pixel-Bild teils auf bis zu 30 Minuten-Generierungszeit.
Da wäre dann schon viel Geduld angesagt…
Verwendet habe ich dann für weitere Tests:
- 1 x AMD Epyc 7282
- 1 x Nvidia RTX A6000 (48 GB VRAM)
- 16 GB RAM
Da gehen die Text-zu-Bild-Generierungen flott von der Hand, was bei der Hardware auch nicht weiter verwunderlich sein dürfte.
Ein eher flotter Sampler wie Euler a braucht bei dieser Hardware ca. 3,5 Sekunden je Iteration – für ein 768 x 768 Pixel-Bild.

Vergleich zu „CPU only“: Was da eine halbe Stunde dauerte, schafft die GPU-beschleunigte KI in etwa einer Minute. Ein deutlicher Unterschied.
Üblicherweise wird für kostenoptimierte Setups eine Nvidia GeForce RTX 3060 mit 12 GB VRAM (nicht 3060 Ti, denn die hat 8 GB VRAM) empfohlen.
Die Installation des Stable Diffusion Web UI geht schnell vonstatten (am Beispiel einer Installation mit Ubuntu-Linux, mehr siehe hier):
- Abhängigkeiten installieren; in meinem Fall (Ubuntu)…
sudo apt install wget git python3 python3-venv - Shell-Script aus dem Github-Repo herunterladen und ausführen…
bash <(wget -qO- https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh) - Model-Checkpoint hinzufügen, siehe hier
- Stable Diffusion Web UI starten…
./webui.sh
Anschließend sollte das Terminal in etwa folgendes ausgeben…
################################################################
Install script for stable-diffusion + Web UI
Tested on Debian 11 (Bullseye)
################################################################
################################################################
Running on user user
################################################################
################################################################
Repo already cloned, using it as install directory
################################################################
################################################################
Create and activate python venv
################################################################
################################################################
Launching launch.py...
################################################################
Python 3.9.12 (main, Apr 5 2022, 06:56:58)
[GCC 7.5.0]
Commit hash: 4af3ca5393151d61363c30eef4965e694eeac15e
Installing requirements for Web UI
Launching Web UI with arguments:
No module 'xformers'. Proceeding without it.
Loading config from: /home/user/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.yaml
LatentDiffusion: Running in v-prediction mode
DiffusionWrapper has 865.91 M params.
Loading weights [2c02b20a] from /home/user/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.ckpt
Applying cross attention optimization (Doggettx).
Model loaded.
Loaded a total of 0 textual inversion embeddings.
Embeddings:
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.Und die Web-Oberfläche ist somit im Browser per 127.0.0.1:7860 zu erreichen.
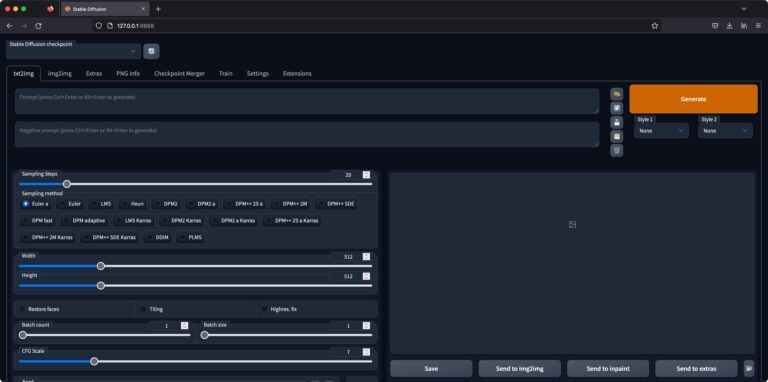
Los kann es gehen mit der KI-Bildgenerierung 🙂
Alternative – KI-Bilder erstellen per Online-Generator
Aktuell geht ein Online-KI-Bildgenerator nach dem anderen an den Start. Das ist derzeit ein Trend in der SaaS-Szene – weitere dürften folgen.
Selbst etablierte Stockbild-Anbieter wie Shutterstock springen auf den KI-Zug und kündigen zusätzlich zum bisherigen Geschäftsmodell KI-Bildgeneratoren an – um beim Beispiel zu bleiben: Shutterstock AI.
Wer sich mit eigener Hardware und selbstinstallierter Software nicht herumschlagen will, erhält mit einem Online-Tool einen einfachen Zugang, um Bilder per Textprompt zu erstellen.
Perfekt zum einfachen Ausprobieren also.
Einige dieser KI-Online-Tools, die mir bereit untergekommen sind:
- Canva (eigentlich ein Online-Foto-Editor, neu jedoch auch mit KI-Generator)
- NightCafe (ausprobieren kostenlos möglich)
- neuroflash (eigentlich auf KI-Texte spezialisiert)
- Jasper AI (AI-Suite)
- Hotpot (5 KI-Bilder kostenfrei erstellen pro Tag)
- Fotor (eigentlich ein Online-Foto-Editor)
- DeepAI (teilweise kostenlos)
- Craiyon (kostenlos; viel Werbung)
- Midjourney (beta)
Es gibt sicher noch einige weitere.
Wer einfach einmal mit einigen Text-Prompts herumspielen möchte kommt hier schnell (und teils auch kostenlos) ans Ziel.
Schaufenster – KI-generierte Bilder
Erste Versuche mit generischen Text-Prompts
Ich fange erstmal mit einigen allgemeinen Text-Prompts an, um mich damit vertraut zu machen.
Schon vorweg – die Text-Prompts können durchaus eine Wissenschaft sein und sind bei komplexen Motiven sehr wichtig, um ein optimales Bild zu erhalten.
Mittlerweile gibt es sogar Startups, die KI-Lösungen für die Generierung von Text-Prompts anbieten – siehe dazu z.B. Phraser (unterstützt Prompts für Stable Diffusion, DALL-E und Midjourney).
Gut scheinen Landschaftsbilder zu funktionieren. Füttere ich den Text-Prompt z.B. mit:
Prompt = „ocean sunset, atlantic ocean, mystic, intense lights“, Dimensions = 768 x 768, Sampler = DPM++ 2M, Sampling Steps = 80, CFG = 7, Batch Count = 4… so kriege ich auf Anhieb ansehnliche KI-Bilder:

Interessant ist dann noch der Negative-Prompt. Will ich z.B. einen Sonnenuntergang ohne Wolken, so kann ich es wie folgt probieren:
Prompt = „ocean sunset, atlantic ocean, mystic, intense lights“, Negative Prompt = „cloudy sky, clouds“ Dimensions = 768 x 768, Sampler = DPM++ 2M, Sampling Steps = 80, CFG = 7, Batch Count = 4Sieht so aus, wie wenn Stable Diffusion meinen Wunsch versteht.

Innenarchitektur und Innengestaltung kann Stable Diffusion ebenfalls gut.
Ich erzeuge mir einige KI-Bilder für ein Wohnzimmer mit folgendem Prompt:
Prompt = „living room with huge tv and sofa, interior design, minimalistic“, Dimensions = 768 x 768, Sampler = Heun, Sampling Steps = 80, CFG = 7, Batch Count = 4Im ersten Wurf sind zwei nette Entwürfe dabei. Kleine Artefakte sind zu erkennen, jedoch liefert die AI/KI hier durchaus eindrucksvolle Ergebnisse ab.


Beide Bilder habe ich übrigens anschließend über die Stable Diffusion Web UI nach oben skaliert.
Und zwar so…
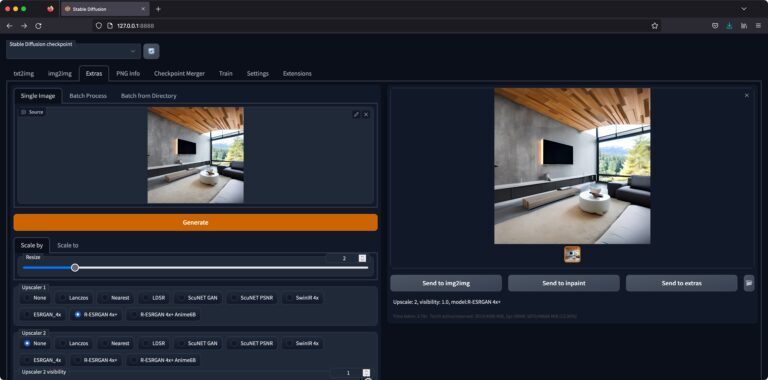
Die eingeschränkte Auflösung ist derzeit noch eine Limitation. 512 Pixel bzw. 768 Pixel (längste Seite) sind derzeit die gängigen Möglichkeiten.
Das reicht für einer Verwendung auf z.B. einer Webseite nicht immer.
Ansonsten ist ja bald Silvester. Als nächster Prompt darf deshalb Feuerwerk am nächtlichen Himmel her. Probiert wie folgt:
Prompt = „nightsky with fireworks, new year“, Dimensions = 768 x 768, Sampler = Euler a, Sampling Steps = 120, CFG = 7, Resize 4x, Upscaler = R-ESRGAN 4x+Nur ein KI-Bild habe ich erzeugt – und das überzeugt direkt.

KI-Bilder erstellen für meinen Technik-Blog
Für meinen Technik-Blog brauche ich jede Menge Bilder.
Teilweise greife ich hier auf Stockbilder zurück.
Gestern habe ich z.B. meinen Beitrag zum Thema OLED-Monitor auf den aktuellen Stand gebracht. Und dafür brauche ich unter anderem ein Beitragsbild.
Einem Monitor sieht man von außen nicht an, dass ein OLED-Panel Verwendung findet.
Mal sehen also, welche KI-Bilder Stable Diffusion hierzu anliefert.
Prompt = „oled monitor on desk, hdr, photo editing“, Negative Prompt = „keyboard, mouse, cables“ Dimensions = 768 x 768, Sampler = Euler a, Sampling Steps = 150, CFG = 7, Resize 2x, Upscaler = R-ESRGAN 4x+Einige Anläufe braucht es hier, um zu einem vorzeigbaren Ergebnis zu kommen…
Das folgende KI-Bild kann sich dann aber sehen lassen.

Zugegeben – ein generisches Bild. Schlecht ist es jedoch nicht.
Was mir nicht gefällt, ist der blumige Wald, der auf dem Monitor zu sehen ist. Eine gute Gelegenheit, um die Inpaint-Funktion des Stable Diffusion Web UI auszuprobieren.
Probieren wir mal, einen Gaming-Monitor daraus zu machen.
Das zu zeichne ich im Browser direkt eine Maske über den Bildbereich, der ausgetauscht werden soll. Grob reicht – den Rest übernimmt die KI.
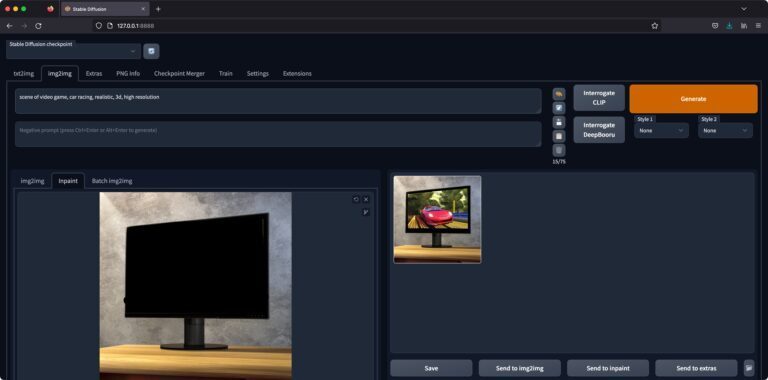
Das hochskalierte Bild sieht dann so aus:

Ansonsten beschäftige ich mich gerade mit USB4-Hubs sowie Thunderbolt 4-Hubs. Mal sehen, ob der KI-Bild-Generator hier etwas brauchbares liefert.
Es wird schon schwieriger…
Prompt = „usb-hub on neutral background“ Dimensions = 768 x 768, Sampler = Heun, Sampling Steps = 150, CFG = 7, Resize 2x, Upscaler = R-ESRGAN 4x+Nach diversen Testläufen mit verschiedenem Text-Prompts wie diesem fällt auf – Stable Diffusion scheint hier neue Port-Designs zu erfinden…

Ich wüßte jedenfalls nicht, was man an diesen von der KI erdachten USB-Hub anschließen könnte 🙂
Im Falle einer zu starken Entfremdung hilft es eigentlich, am CFG-Scale zu schrauben.
CFG steht für „classifier-free guidance“ und ein höherer Wert heißt, dass Stable Diffusion sich enger an den verwendeten Text-Prompt zu halten hat.
Ich habe es mit anderen Einstellungen für den CFG-Scale probiert, bis hin zu:
Prompt = „usb-hub on neutral background“ Dimensions = 768 x 768, Sampler = Heun, Sampling Steps = 150, CFG = 25, Resize 2x, Upscaler = R-ESRGAN 4x+Auch hier geht der KI-Bildgenerator jedoch „kreativ“ mit den Anschlüssen um 🙂

KI-Bilder erstellen für meinen Reise-Blog
Einen nächsten Versuch starte ich für meinen Reise-Blog.
Bei Trip Angkor geht es rund um Kambodscha-Reisen.
Ich sage eines gleich vorweg – selbst bei guten Bildergebnissen würde ich ein KI-Bild einer Sehenswürdigkeit nie für einen Reise-Blog verwenden.
Der Grund ist ganz einfach.
Macht sich einer meiner Leser schließlich auf die Reise und steht vor der Sehenswürdigkeit, hätte ich dann doch den Anspruch, ihn mit einer „echten“ Aufnahme versorgt zu haben.
Aber auch bei einer Reise-Webseite kann man an der ein oder anderen Stelle mit Symbolbildern arbeiten.
Vielleicht etwas zu Stränden in Kambodscha?
Prompt = „beach in cambodia, island, panoramic“ Dimensions = 768 x 768, Sampler = Euler a, Sampling Steps = 150, CFG = 7, Resize 2x, Upscaler = R-ESRGAN 4x+Das Ergebnis ist nicht schlecht und erinnert mich an die Strände, die sich auf den Inseln Koh Rong und Koh Rong Samloem bei Sihanoukville finden.

Nochmal ein neuer Versuch zu einem KI-generierten Reisebild.
Wie kommt man in Kambodscha herum?
Am einfachsten per Bus (es gibt nur wenige Flughäfen im Land). Zum Thema Busreisen in Kambodscha könnte ich mir schon eher vorstellen, ein KI-Bilder zu erstellen (und auch zu verwenden).
Prompt = „bus on countryside road in cambodia“ Dimensions = 768 x 768, Sampler = DPM++ 2M Karras, Sampling Steps = 120, CFG = 7, Resize 2x, Upscaler = R-ESRGAN 4x+Da kommt etwas brauchbares heraus – so in etwa darf man sich eine Fahrt mit dem Bus auf einer ländlichen Straße in Kambodscha auch vorstellen:

Nicht nur KI-Bilder aus Text… weitere Funktionen und Extras
- Text-zu-Bild
- Bild-zu-Bild
- Rescaling / Upscaling
- Inpainting / Outpainting
- weitere Features siehe hier
Rechtliches und Ethisches
Ein paar Gedanken dazu, was KI-Bilder im Alltag bedeuten, habe ich mir auch gemacht. Folgendes sind nur meine persönliche Gedanken dazu…
Zunächst einmal denke ich an Nutzer, denen KI-Bilder z.B. auf einer Webseite oder in Social Media dargeboten werden. Die sind teils so gut und realistisch, dass man der Sache auf den Leim gehen kann und ein „echtes“ Foto vermuten könnte.
Eine Kennzeichnung als „KI-Bild“, „KI-Foto“, „KI-Illustration“, „KI-Kunst“ oder so ähnlich fände ich vor diesem Hintergrund schon einmal angeraten.
Damit KI-Bildgeneratoren brauchbare Ergebnisse zu (fast) jedem Text-Prompt liefern, müssen die zu Grunde liegende Modelle mit jeder Menge Trainingsdaten gefüttert werden.
Dafür dürfte in den wenigsten Fällen ein explizites Einverständnis des Bildurhebers vorliegen. Von einem etablierten Vergütungsmodell für Trainingsdaten habe ich auch noch nichts gehört.
Ein anderer Aspekt ist, dass die erzeugten Bilder teils so gut sind, dass sich einige Künstler, Fotografen usw. bereits Sorgen machen, künftig von der KI ausgestochen zu werden.
Eine Frage wäre dann auch noch, ob man sich als Webseiten- oder Blogbetreiber, der KI-Bilder verwendet, sich rechtliche Probleme einhandeln könnte.
Da wären zunächst die Nutzungsbedingungen des jeweiligen KI-Tools zu beachten.
Das Urheberrecht stellt m.W. bislang menschliches Schaffen in den Mittelpunkt der Schutzwürdigkeit – und das wäre bei einem rein computergenerierten Bild vermutlich zu verneinen.
Kritisch würde es aber sicherlich, wenn das KI-Bild deutlich erkennbar Teile z.B. eines geschützten Werkes, einer Marke oder einer Person zeigt.
Dass die KI anstößige Inhalte erstellt – ebenfalls nicht auszuschließen.
Wie KI-Kunst und KI-Bilder genau einzustufen sind, das wird Juristen sicher noch beschäftigen.
Naja, im Grundsatz gilt ja weiter: Hat eine Organisation oder Person etwas an einem Bild zu beanstanden, hat im Zweifelsfall derjenige, der es verbreitet, dafür geradezustehen – ob nun KI-Bild oder nicht.
Mein Fazit – KI ist interessant, aber ich bleibe (vorerst) bei „klassischen“ Bildquellen
Wirklich beeindruckend ist, welche gute Ergebnisse KI-Bildgeneratoren bereits jetzt liefern können.
Der Fantasie sind dabei keine Grenzen gesetzt.
Die KI erstellt auch Bilder, die man nie vor die eigene Linse bekommen wird und die sich so auch in keiner Stockbilder-Datenbank findet.
Ein Affe mit einem Cowboyhut beim Popcorn-Essen im Kino? Kein Problem!

Probleme gibt es jedoch auch.
Für manche Motive gibt es auch nach langem herum probieren mit verschiedenen Text-Prompts keine guten Ergebnisse.
Da ist man bei einer klassischen Bildrecherche oder sogar mit der eigenen Kamera teils schneller.
Weitere Einschränkungen sind z.B. die derzeit noch geringe Auflösung und das gelegentliche Auftreten von störenden Artefakten und sonstigen Bildfehlern.
Ich denke jedoch, man darf sich darauf einstellen: Künftig sieht man vermehrt Bilder, die aus einem KI-Bild-Generator stammen.

Hallo Patrick, wir finden Deinen Tech-Junkies Blog super. Gratulation!
Nun. Wer sind „wir“? SHA.ART – ein Künstlerkollektiv aus Wien, das in einem ziemlich großformatigen Kunstprojekt im öffentlichen Raum das Thema AI explorieren will. Es geht um interaktive multisensorische Kunst, die in einem 250 Jahre alten historischen Gebäudeensemble projiziert werden soll.
Softwaretechnisch arbeiten wir mit VVVV (Visuals) und max/msp (Audio). Aber wir grübeln gerade herum, wie wir die jüngsten Revolutionen auf dem AI-Bereich in das Projekt quasi einbinden können.
Wir haben da ästhetisch und inhaltliche Vorstellungen … sprechen auch mit Jungs von der Ars Electronica … aber irgendwie möchten wir da gerne ganz vorne den state-of-the-art mitnehmen.
Frage: Weißt Du viel darüber? Du wirkst wie ein toller Experte auf diesem Gebiet. Kennst Du persönlich aus Deinem Umfeld Programmierer, die auf sowas Lust hätten?
Hast Du selbst Lust mal darüber zu reden?
Herzliche Grüße aus Wien!
SHA.ART
Hallo Bob,
vielen Dank für Deinen netten Kommentar!
Ich war gerade auf Eurer Webseite – beeindruckende Projekte. Ich schätze Kunst, die mit der Architektur verschmilzt, sich auch in den Alltag einfügt.
Es gibt Programmierer, die an den KI-Modellen selbst arbeiten und solche, die existierende KI-Tools über APIs usw. in ihre Projekte einbinden. Ersteres ist ein erlauchter Kreis, für letzteres sind die Hürden nicht hoch (zumindest für die ersten Schritte). Der Hype um KI-Bildgenerierung ist ja gerade erst angelaufen – da gibt es also Niemanden mit langjähriger Erfahrung.
Deswegen: Ich schätze, eine gute Wahl ist auch ein Programmierer, der sich mit Creative Coding auskennt (ich habe keine Erfahrung damit) und Zeit hat, sich neu in die KI-Tools einzuarbeiten.
Viele Grüße,
Patrick
Ich bin begeisterter Nutzer von Stable Diffusion, aber momentan hat Midjourney die Top Position und scheint diese auch zu halten.
Hier ein paar meiner Beispiele und Prompts, die auch gerne jeder verwenden und kopieren kann:
https://lustighoch5.de/prompts-fuer-midjourney-wunderschoene-bilder-mit-kuenstlicher-intelligenz/
Danke!
Eine schöne und wirklich hilfreiche Übersicht hast du da zusammengestellt! Ich bin Künstlerin und experimentiere ebenfalls gerade mit KI Bildgeneratoren rum. Mein Zwischenfazit: Ein schöner Weg, um erste Ideen für neue Gemälde zu visualisieren und Entwürfe zu gestalten, mit denen man dann mit echter Farbe und Pinsel auf Leinwand weiterarbeiten kann. Ich sehe die diversen KI Tools daher als „Assistent“, der mir zuarbeitet und das finde ich richtig spannend!
Hallo Anja,
super, danke für Dein Feedback.
Viele Grüße,
Patrick